1. 분류
- 지도학습의 대표적인 유형
- 학습 데이터로 주어진 데이터의 피처와 레이블값(결정 값, 클래스 값)을 머신러닝 알고리즘으로 학습하여 모델을 생성
- 생성된 모델에 새로운 데이터 값이 주어졌을때 미지의 레이블 값을 예측하는 것
1.1 분류를 구현할 수 있는 다양한 머신러닝 알고리즘
- 나이브 베이즈(Naive Bayes) : 베이즈 통게와 생성 모델에 기반한 나이브 베이즈
- 로지스틱 회귀(Logistic Regression) : 독립변수와 종속변수의 선형 관계성에 기반한 로지스틱 회귀
- 결정 트리(Decision Tree) : 데이터 균일도에 따른 규칙 기반의 결정 트리
- 서포트 벡터 머신(Support Vector Machine) : 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡터 머신
- 최소 근접 알고리즘(Nearest Neighbor) : 근접 거리를 기준으로 하는 최소 근접 알고리즘
- 신경망(Neural Network) : 심층 연결 기반의 신경망
- 앙상블(Ensemble) : 서로 다른 머신러닝 알고리즘을 결합한 앙상블
1.2 앙상블
: 일반적으로 배깅(Bagging)과 부스팅(Boosting) 방식으로 나뉨
- 배깅 (Bagging)
: 랜덤 포레스트 (Random Forest)- 배깅 방식의 대표적
뛰어난 예측 성능, 상대적으로 빠른 수행시간, 유연성으로 애용되는 알고리즘
- 부스팅 (Boosting)
:그래디언트 부스팅 : 뛰어난 예측 성능, 수행 시간 너무 오래걸려 최적화 모델 튜닝 어려움
: XgBoost(eXtra Gradient Boost)와 LightGBM
성능 좋고 수행 시간 단축시키는 알고리즘 등장하며 정형 데이터 분류 영역에서 가장 활용도 높은 알고리즘으로 자리잡음
2. 결정트리
: 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 것
: 규칙을 가장 쉽게 표현하는 방법은 if/else 기반으로 나타내는 것으로, 룰 기반의 프로그램에 적용되는 if, else를 자동으로 찾아내 예측을 위한 규칙을 만드는 알고리즘
: 데이터의 어떤 기준을 바탕으로 규칙으로 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능을 크게 좌우함

- 규칙 노드 : 규칙 조건, 데이터셋의 피처가 결합해 규칙 조건을 만들때마다 생성됨
- 리프 노드 : 결정된 클래스 값
- 서브 트리 : 새로운 규칙 조건마다 서브 트리 생성
Q. 가능한 적은 결정 노드로 높은 예측 정확도를 가지려면 ???
- 데이터를 분류할 때 최대한 많은 데이터셋이 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야 함
- 최대한 *균일한 데이터셋을 구성할 수 있도록 분할(split)해야 함
* 균일도 측정 방법: 엔트로피를 이용한 정보 이득(Information Gain)지수와 지니 계수
- 정보이득지수
: 엔트로피는 주어진 데이터 집합의 혼잡도를 의미하는데 서로 다른 값이 섞여 있으면 엔트로피가 높고, 같은 값이 섞여 있으면 엔트로피가 낮다. 정보 이득 지수는 1에서 엔트로피 지수를 뺀 값(1 - 엔트로피지수)이다. 결정 트리는 이 정보 이득 지수가 높은 속성을 기준으로 분할한다.
- 지니 계수
: 원래 경제학에서 불평등 지수를 나타낼 때 사용하는 계수로 0이 가장 평등하고 1로 갈수록 불평등하다. 머신러닝에서는 지니 계수가 낮을수록 데이터 균일도가 높은 것으로 해석해 지니 계수가 낮은 속성을 기준으로 분할한다
: 결정 트리는 균일도라는 룰을 기반으로 하고 있어서 알고리즘이 쉽고 직관적이다. 하지만 트리의 깊이가 커지고 복잡해지면서 과적합이 될 수 있다는 단점 또한 지닌다.
: 결정 트리는 균일도라는 룰을 기반으로 하고 있어서 알고리즘이 쉽고 직관적이다. 하지만 트리의 깊이가 커지고 복잡해지면서 과적합이 될 수 있다는 단점 또한 지닌다.
- min_samples_split : 노드를 분할하기 위한 최소한의 샘플 데이터 , default = 2 ( 작게 설정할 수록 과적합 가능성 증가 )
- min_samples_leaf : 말단 노드가 되기 위한 최소한의 샘플 데이터 수, 비대칭적 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있기 때문에 작게 설정해 주어야 한다. ( 과적합 제어 용도 )
- max_features : 최적의 분할을 위해 고려할 최대 피처 개수, default = None ( 모든 피처를 사용해 분할 수행 ) ( int, float, sqrt = auto, log )
- max_depth : 트리의 최대 깊이를 규정 , default = None ( 완벽하게 클래스 결정 값이 될 때까지 깊이를 계속 키움 or 노드가 가지는 데이터 개수가 min_samples_split보다 작아질 때까지 계속 깊이를 증가시킴 )
- max_leaf_nodes : 말단 노드의 최대 개수
3. 붓꽃 데이터를 이용한 결정트리 모델의 학습과 예측
#붓꽃 데이터를 이용한 결정 트리 모델의 학습과 예측
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
# DecisionTree Classifier 생성
dt_clf = DecisionTreeClassifier(random_state=156)
iris_data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size = 0.2, random_state = 11)
dt_clf.fit(X_train, y_train)DecisionTreeClassifier(random_state=156)#Graphiz 사용
from sklearn.tree import export_graphviz
# export_graphviz()의 호출 결과로 out_file로 지정된 tree.dot 파일을 생성함
export_graphviz(dt_clf, out_file = "tree.dot", class_names = iris_data.target_names, \
feature_names = iris_data.feature_names, impurity = True, filled = True)
import graphviz
# 위에서 생성된 tree.dot 파일을 Graphviz가 읽어서 주피터 노트북상에서 시각화
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
: 생성 로직을 미리 제어하지 않으면, 완벽하게 클래스 값을 구별하기 위해 트리노드를 계속해서 생성 됨
=> 모델 과적합 되기 쉬움
- petal length(cm) ≤ 2.45 : 자식 노드를 만들기 위한 규칙 노드
- gini : value=[]로 주어진 데이터 분포에서의 지니 계수
- samples : 현 규칙에 해당하는 데이터 건수
- value=[] : 클래스 값 기반의 데이터 건수
min_samples_splits=x
자식노드로 분할할 수 있는 최소한의 샘플 데이터개수는 x개임을 의미함.
Ex) min_samples_splits=4 이면 샘플데이터가 (0,2,1)개일 때 자식노드로 분화할 수 없다.
min_samples_leaf=x
leaf노드가 될 수 있는 조건은 디폴트로 1이지만, 값을 설정하면 리프노드가 될 수 있는 샘플데이터 건수의 최소값을 말한다. 즉, 샘플 데이터개수 x개를 만족하고 한쪽으로 몰릴 때 leaf노드가 될 수 있음을 의미함.
Ex) min_sampels_leaf=2이고, sample=7이라면 2와 5개로 나누어질 수가 없다.
둘의 차이는 거의 없다. 만약 샘플수가 4인데, splits=3, leaf=4의 값을 준다면? leaf=4이므로 멈춘다.만약 샘플수가 4인데 splits=4, leaf=4라면? splits=4이므로 멈춘다.
feature importance
결정트리 알고리즘이 학습을 통해 규칙을 정하는데 있어 피처의 중요한 역할 지표 제공
4. 결정트리 과적합
: 분류용 가상데이터를 생성해주는 make_classification( ) 에서 n_feature는 독립변수의 수
: n_informatives는 종속변수 데이터와 상관있는 독립변수의 수
: n_classes는 종속변수의 레이블데이터 개수
: n_clusters_per_class는 한 클래스에 들어간 cluster(군집)의 수를 의미한다.
from sklearn.tree import DecisionTreeClassifier
# 특정한 트리 생성 제약 없는 결정 트리의 학습과 결정 경계 시각화
dt_clf = DecisionTreeClassifier().fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)
# 일부 이상치 데이터까지 분류하기 위한 분할이 자주 일어나서 결정 기준 경계가 너무 많아졌다.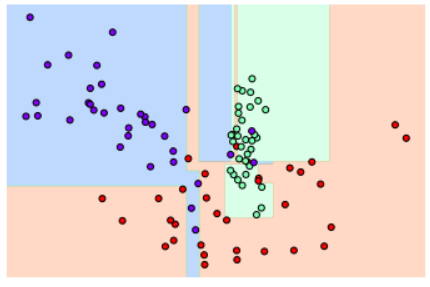
# min_samples_leaf = 6으로 트리 생성 조건을 제약
dt_clf = DecisionTreeClassifier(min_samples_leaf = 6).fit(X_features, y_labels)
visualize_boundary(dt_clf, X_features, y_labels)
5. 결정트리 실습 -사용자 행동 인식 데이터세트
# 중복된 피처명이 얼마나 있는지 확인
feature_dup_df = feature_name_df.groupby('column_name').count()
print(feature_dup_df[feature_dup_df['column_index'] > 1].count())
feature_dup_df[feature_dup_df['column_index'] > 1].head()
# 총 42개의 column이 중복되어 있음column_index 42
dtype: int64
# 원본 피처명에 _1 or _2를 추가로 부여해 새로운 피처명을 가지는 DataFrame을 반환하는 함수
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(), columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1])
if x[1] > 0 else x[0], axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis=1)
return new_feature_name_dfimport pandas as pd
def get_human_dataset( ):
# 공백으로 분리 -> sep인자를 \s+
feature_name_df = pd.read_csv('./UCI_HAR_Dataset/features.txt', sep ='\s+', header = None, names=['column_index', 'column_name'])
# 중복된 피처명을 수정
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 column으로 부여하기 위해
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 핓 데이터 세트, 테스트 피처 데이터
X_train = pd.read_csv('./UCI_HAR_Dataset/train/X_train.txt', sep ='\s+', names=feature_name)
X_test = pd.read_csv('./UCI_HAR_Dataset/test/X_test.txt', sep ='\s+', names=feature_name)
# 학습 레이블, 테스트 레이블
y_train = pd.read_csv('./UCI_HAR_Dataset/train/y_train.txt', sep ='\s+', header = None, names=['action'])
y_test = pd.read_csv('./UCI_HAR_Dataset/test/y_test.txt', sep ='\s+', header = None, names=['action'])
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()- 로드한 학습용 데이터셋 살펴보기
print('## 학습 피처 데이터셋 info() ##')
print(X_train.info())
# 7352개의 레코드로 561개의 피처를 지닌다.## 학습 피처 데이터셋 info() ##
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7352 entries, 0 to 7351
Columns: 561 entries, tBodyAcc-mean()-X to angle(Z,gravityMean)
dtypes: float64(561)
memory usage: 31.5 MB
None: 학습 데이터 세트는 7352개의 레코드로 561개의 피처를 갖고 있음.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(random_state = 156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('결정 트리 예측 정확도: {0:.4f}'.format(accuracy))
print('DecisionTreeClassifier 기본 하이퍼 파라미터 : ', dt_clf.get_params())결정 트리 예측 정확도: 0.8548
DecisionTreeClassifier 기본 하이퍼 파라미터 : {'ccp_alpha': 0.0, 'class_weight': None, 'criterion': 'gini', 'max_depth': None, 'max_features': None, 'max_leaf_nodes': None, 'min_impurity_decrease': 0.0, 'min_impurity_split': None, 'min_samples_leaf': 1, 'min_samples_split': 2, 'min_weight_fraction_leaf': 0.0, 'random_state': 156, 'splitter': 'best'}- 결정 트리의 트리 깊이가 예측 정확도에 주는 영
from sklearn.model_selection import GridSearchCV
params = { 'max_depth' : [6, 8, 10, 12, 16, 20, 24] }
grid_cv = GridSearchCV(dt_clf, param_grid = params, scoring = 'accuracy', cv=5, verbose =1)
grid_cv.fit(X_train, y_train)
print('최고 평균 정확도 수치' ,grid_cv.best_score_)
print('최적 하이퍼 파라미터', grid_cv.best_params_)Fitting 5 folds for each of 7 candidates, totalling 35 fits
최고 평균 정확도 수치 0.8513444970102249
최적 하이퍼 파라미터 {'max_depth': 16}# GridSearchCV 객체의 cv_results_ 속성을 DataFrame으로 생성
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
# max_depth 파라미터 값과 그 때의 테스트 세트, 학습 데이터 세트의 정확도 수치 추출
cv_results_df[['param_max_depth', 'mean_test_score']]
# max_depth 변화에 따른 값 측정
max_depths = [6,8,10,12,16,20,24]
# max_depth 값을 변화시키면서 그때마다 학습과 테스트 세트에서의 예측 성능 측정
for depth in max_depths:
dt_clf = DecisionTreeClassifier(max_depth=depth, random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('max_depth = {0}, accuracy = {1:.4f}'.format(depth, accuracy))max_depth = 6, accuracy = 0.8558
max_depth = 8, accuracy = 0.8707
max_depth = 10, accuracy = 0.8673
max_depth = 12, accuracy = 0.8646
max_depth = 16, accuracy = 0.8575
max_depth = 20, accuracy = 0.8548
max_depth = 24, accuracy = 0.8548- min_samples_split을 활용한 grid search 생략
: grid search 후 .bestestimator 에 최적의 하이퍼 파라미터가 적용된 모델이 저장된다는 것을 알면된다.
# 피처 중요도 시각화
import seaborn as sns
ftr_importances_values = best_df_clf.feature_importances_
# Top 중요도로 정렬을 쉽게 하고, Seaborn의 막대그래프로 표현하기 위한 Series변환
ftr_importances = pd.Series(ftr_importances_values, index = X_train.columns)
# 중요도값 순으로 Series를 정렬
ftr_top10 = ftr_importances.sort_values(ascending = False)[:10]
plt.figure(figsize=(8,6))
plt.title('Feature importances Top10')
sns.barplot(x=ftr_top10, y = ftr_top10.index)
plt.show()
'Data > 머신러닝' 카테고리의 다른 글
| [파이썬머신러닝완벽가이드]GBM(Gradient Boosting Machine) (1) | 2023.07.02 |
|---|---|
| [파이썬머신러닝완벽가이드]03.평가(2) (0) | 2023.05.13 |
| [파이썬머신러닝완벽가이드]03.평가(1) (0) | 2023.05.06 |
| [파이썬머신러닝완벽가이드]02.사이킷런으로 시작하는 머신러닝(2) (0) | 2023.04.28 |
| [파이썬머신러닝완벽가이드]02.사이킷런으로 시작하는 머신러닝(1) (0) | 2023.04.20 |



