GBM의 개요 및 실습
부스팅 알고리즘은 여러 개의 학습기를 순찾거으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식이다.
대표적:AdaBoost(Adaptive boosting)와 그래디언트 부스트
- AdaBoost(Adaptive boosting) : 오류 데이터에 가중치를 부여하면서 부스팅을 수행하는 대표적인 알고리즘
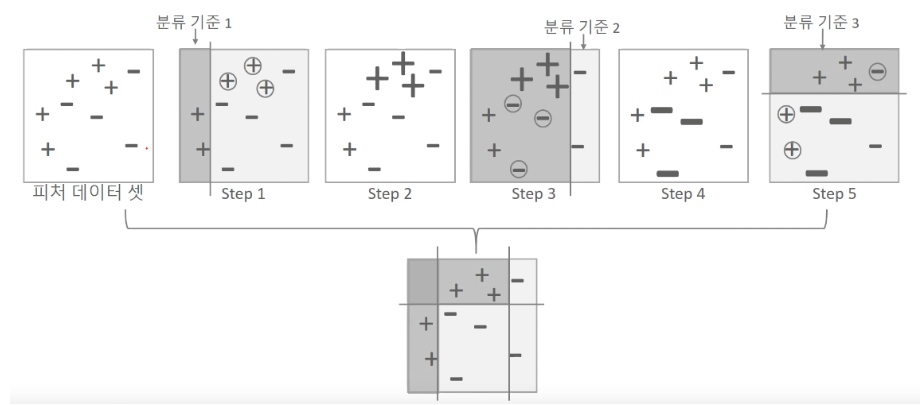
동그라미 형태가 잘못된 오류 데이터이고, 이 오류 데이터에 대해서 가중치 값을 부여하는방식으로 학습을 진행한다.
->adaboost 동작 원리
https://bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-14-AdaBoost
머신러닝 - 14. 에이다 부스트(AdaBoost)
본 챕터에서는 부스팅 기법 중 가장 기본이 되는 AdaBoost에 대해 알아보겠습니다. 부스팅에 대해서 잘 모르신다면 '머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)'을 참
bkshin.tistory.com
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# 데이터 불러오기
# kaggle data
data = pd.read_csv("C:/otto_train.csv")
data.head()# shape확인
nCar = data.shape[0] # 데이터 개수
nVar = data.shape[1] # 변수 개수
print('nCar: %d' % nCar, 'nVar: %d' % nVar )
nCar: 61878 nVar: 95#변수제거(axis=열)
data= data.drop(['id'],axis=1)
# 타겟 변수의 형변환
mapping_dict = {'Class_1' : 1,
'Class_2' : 2,
'Class_3' : 3,
'Class_4' : 4,
'Class_5' : 5,
'Class_6' : 6,
'Class_7' : 7,
'Class_8' : 8,
'Class_9' : 9,}
after_mapping_target = data['target'].apply(lambda x : mapping_dict[x])
after_mapping_target0 1
1 1
2 1
3 1
4 1
..
61873 9
61874 9
61875 9
61876 9
61877 9
Name: target, Length: 61878, dtype: int64target gudxork 1~9로 변경한 후 classification 을 진행
# features/target, train/test dataset 분리
feature_columns = list(data.columns.difference(['target']))
X = data[feature_columns]
y = after_mapping_target
train_x, test_x, train_y, test_y = train_test_split(X, y, test_size = 0.2, random_state = 42) # 학습데이터와 평가데이터의 비율을 8:2 로 분할|
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape) # 데이터 개수 확인adaboost
# 라이브러리
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 가장 기본적인 AdaBoost
clf = AdaBoostClassifier(n_estimators=100, random_state=0)
# n_estimators = 부스팅이 종료되는 추정기의 최대수, random_state=0->default, 무작위로 제어
clf.fit(train_x, train_y)
# train_x, train_y classifier/regressor 구축
pred=clf.predict(test_x)
print(accuracy_score(test_y, pred))0.6771170006464124정확도는 약 68% 정도
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html
sklearn.ensemble.AdaBoostClassifier
Examples using sklearn.ensemble.AdaBoostClassifier: Classifier comparison Discrete versus Real AdaBoost Multi-class AdaBoosted Decision Trees Plot the decision surfaces of ensembles of trees on the...
scikit-learn.org
- 그래디언트 부스트
내부예측기를 Decision Tree를 사용하는 방법
https://m.blog.naver.com/gdpresent/221717318894
부스팅(Boosting) [내가 공부한 머신러닝 #19.]
내가 공부한 머신러닝 20 이번에는 Boosting방식을 적용한 앙상블을 만져볼 것인데, 뭐 이전에 얘기 다 나...
blog.naver.com
XGBOOST
- 트리기반의 앙상블에서가장 많이 각광받는 알고리즘
- Boosting은 여러개의 약한 Decision Tree를 조합하는 방식이라면 XGBoost는 분산환경에서도 실행할 수 있는 라이브러리
- 여러개의 Decision Tree를 조합해서 사용하는 Ensemble 알고리즘
XGBOOST 적용해서 위스콘신 유방암 예측
데이터를 DataFraem으로 로드 & 탐색
import xgboost as xgb
from xgboost import plot_importance
from xgboost import XGBClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
import warnings
warnings.filterwarnings('ignore')
X_features= dataset.data
y_label = dataset.target
cancer_df = pd.DataFrame(data=X_features, columns=dataset.feature_names)
cancer_df['target']= y_label
cancer_df.head(3)
다양한 속성값 확인 가능
print(dataset.target_names)
print(cancer_df['target'].value_counts())['malignant' 'benign']
1 357
0 212
Name: target, dtype: int64데이터셋 분할(학습용/테스트용/검증용)
# cancer_df에서 feature용 DataFrame과 Label용 Series 객체 추출
# 맨 마지막 칼럼이 Label임. Feature용 DataFrame은 cancer_df의 첫번째 칼럼에서 맨 마지막 두번째 칼럼까지를 :-1 슬라이싱으로 추출.
X_features = cancer_df.iloc[:, :-1]
y_label = cancer_df.iloc[:, -1]
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test=train_test_split(X_features, y_label,
test_size=0.2, random_state=156 )
# 위에서 만든 X_train, y_train을 다시 쪼개서 90%는 학습과 10%는 검증용 데이터로 분리
X_tr, X_val, y_tr, y_val= train_test_split(X_train, y_train, test_size=0.1, random_state=156 )
print(X_train.shape , X_test.shape)
print(X_tr.shape, X_val.shape)(455, 30) (114, 30)
(409, 30) (46, 30)ML 알고리즘 학습/예측 수행
XGBoost 하이퍼 파라미터 설정
params = { 'max_depth':3,
'eta': 0.05,
'objective':'binary:logistic',
'eval_metric':'logloss'
}
num_rounds = 400
# 학습 데이터 셋은 'train' 또는 평가 데이터 셋은 'eval' 로 명기합니다.
eval_list = [(dtr,'train'),(dval,'eval')] # 또는 eval_list = [(dval,'eval')] 만 명기해도 무방.
# 하이퍼 파라미터와 early stopping 파라미터를 train( ) 함수의 파라미터로 전달
xgb_model = xgb.train(params = params , dtrain=dtr , num_boost_round=num_rounds , \
early_stopping_rounds=50, evals=eval_list )
pred_probs = xgb_model.predict(dtest)
print('predict( ) 수행 결과값을 10개만 표시, 예측 확률 값으로 표시됨')
print(np.round(pred_probs[:10],3))
# 예측 확률이 0.5 보다 크면 1 , 그렇지 않으면 0 으로 예측값 결정하여 List 객체인 preds에 저장
preds = [ 1 if x > 0.5 else 0 for x in pred_probs ]
print('예측값 10개만 표시:',preds[:10])predict( ) 수행 결과값을 10개만 표시, 예측 확률 값으로 표시됨
[0.845 0.008 0.68 0.081 0.975 0.999 0.998 0.998 0.996 0.001]
예측값 10개만 표시: [1, 0, 1, 0, 1, 1, 1, 1, 1, 0]모델평가
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
f1 = f1_score(y_test,pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
# ROC-AUC print 추가
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))
get_clf_eval(y_test , preds, pred_probs)시각화
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_model, ax=ax)
plt.savefig('p239_xgb_feature_importance.tif', format='tif', dpi=300, bbox_inches='tight')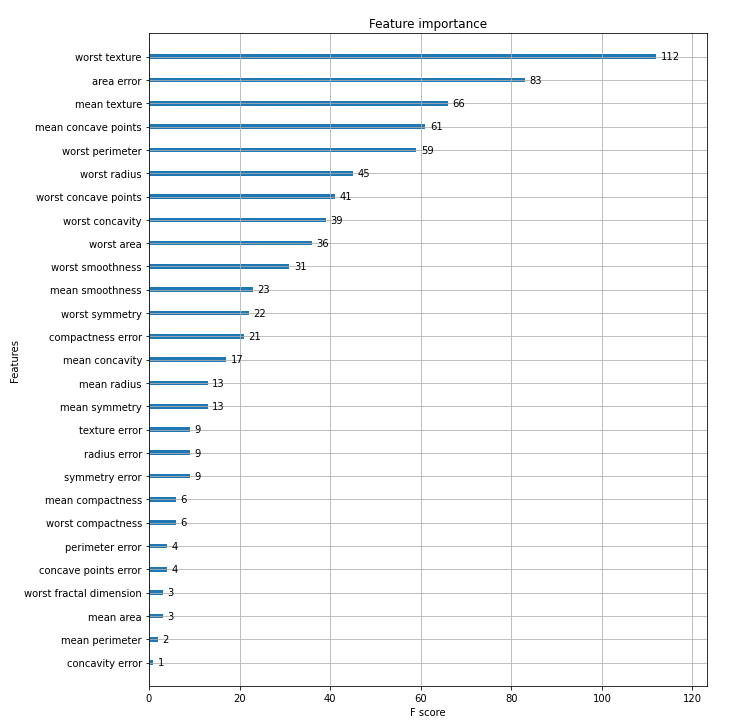
'Data > 머신러닝' 카테고리의 다른 글
| [파이썬머신러닝완벽가이드]04.분류(1) (0) | 2023.05.20 |
|---|---|
| [파이썬머신러닝완벽가이드]03.평가(2) (0) | 2023.05.13 |
| [파이썬머신러닝완벽가이드]03.평가(1) (0) | 2023.05.06 |
| [파이썬머신러닝완벽가이드]02.사이킷런으로 시작하는 머신러닝(2) (0) | 2023.04.28 |
| [파이썬머신러닝완벽가이드]02.사이킷런으로 시작하는 머신러닝(1) (0) | 2023.04.20 |



